| 摘要:运维的阶段可能很多场合很多人都讲过,但这里有一点不一样,从人肉运维到自动化运维,再到 AIOps 中间应该还有个过渡阶段,当然大家也可以把它理解为 AIOps 的初级阶段。 |

讲师介绍:
首先简单介绍一下我自己,我叫范伦挺,也算是运维的老兵了,大概 2008年开始进入运维行业,现在就职于阿里巴巴计算平台事业部大数据基础工程技术团队。
先后负责过阿里 MaxCompute、AnalyticDB、PAI等大数据产品运维工作,目前主要专注于实时计算平台 Stream-Compute 的运维工作。
今天我的演讲主要从以下四部分来讲:
一、运维进阶;
二、一体化运维平台;
三、重点介绍一下 DataOps 实践
最后一部分是在 AIOps 方向的探索

1. 运维进阶
运维的阶段可能很多场合很多人都讲过,但这里有一点不一样,从人肉运维到自动化运维,再到 AIOps 中间应该还有个过渡阶段,当然大家也可以把它理解为 AIOps 的初级阶段。
那这个和 AIOps 之间的区别是什么?DataOps 从理论上来讲也是一样,主要依据于数据加各种算法模型能够给出一个比较智能的结果。它相比 AIOps 更多是在于它给出的结果是一个辅助决策的作用,就你不敢拿它的结论直接去对接你的自动化平台。
AIOps 实际在人这个决策上会有很大的区别,只是进行一些异常的响应,平常没事就不需要人的干预。DataOps 还是需要经过人的决策过程,这是两者之间最大的区别,目前还是主要处在 DataOps 的阶段,离 AIOps 还是有一定距离。

2. 一体化运维平台
这是整个阿里巴巴计算平台事业部所负责的一些技术架构,下面有两大分布式计算引擎,在此之上会有很多的大数据计算平台,像刚刚提到 MaxCompute 等等,各种类型的离线计算平台、实时计算平台、存储平台、数据通道等等都是基于下面两个大的计算引擎去构建的,这整体的物理体量在10w+以上。
这里有几个可能大家比较熟悉一点的,GMV 媒体大屏,这就是基于实时计算的计算平台做的汇总。生意参谋,提供行业内的各种营销数据。

那为了解决或者运维好多引擎多平台的应用,我们构建了这样一个分层的运维解决方案,整体来讲我们把运维平台也抽象成了三层:
运维的 laaS 层,这些主要依赖于集团的基础设施,不需要我们部门投很多的力量去解决的。
基于它之上就有所谓的运维 PaaS 层,也包括公共服务的用户管理、角色管理。
那再上一层 PaaS,客户对于这些平台所希望得到的功能诉求也是不一样的,所以应用这一层个性化的,基于公共的服务层快速构建自己的应用站点。

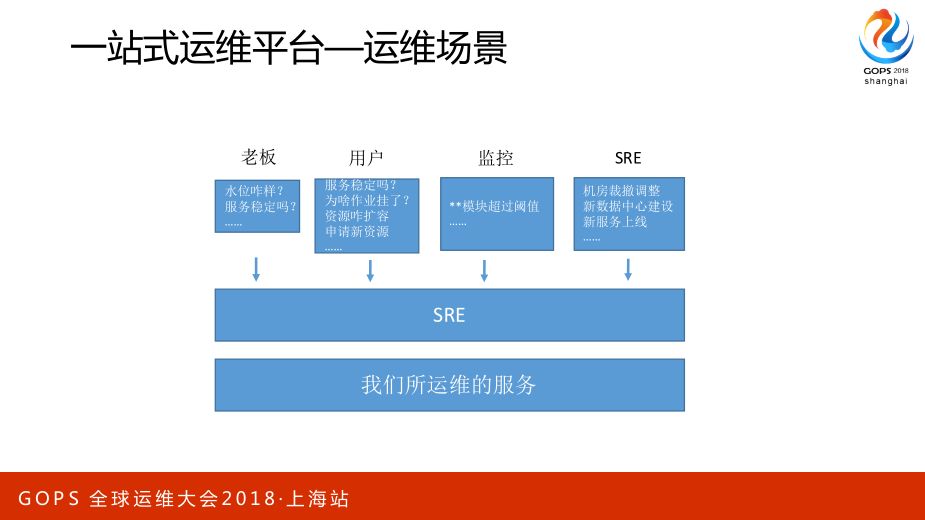
我们看一下所谓的一站式运维平台到底在解决什么问题,因为不同公司的场景不一样,是不是一定要到那繁杂的程度也是不一定的,能解决自己的问题就好。你看看运维在这角色中到底每天在忙什么,是什么样的人来找你,他们找你是因为什么样的事情。
实际上这里大的类别来讲就是解决两个信息流的问题:
一是信息流由下往上,就是看“看”的问题,到底服务稳不稳定、服务运行怎么样;
二是命令流,从上往下,包括自己服务的上下线等等,所以自己去规划的时候一般是运维平台要解决的问题从“看”和“做”两方面,去做一些解决自己痛点的落地。
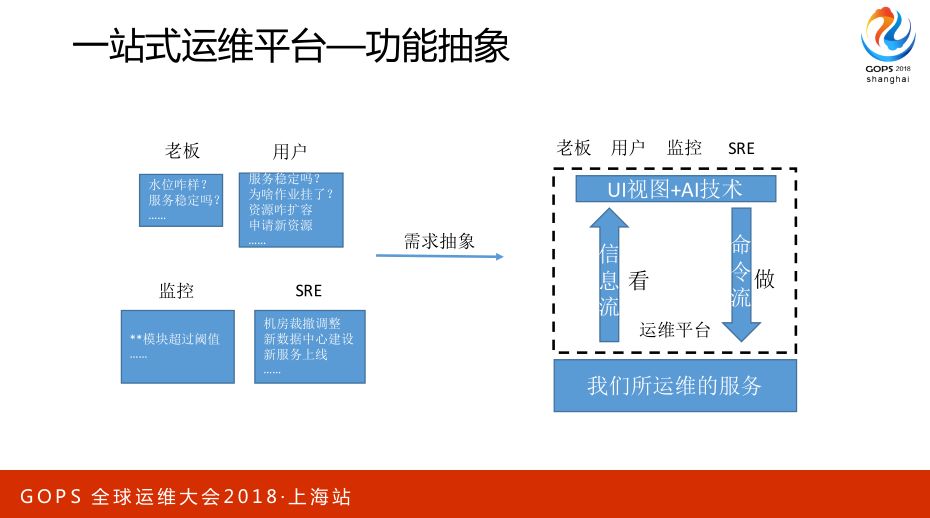
所谓的自动化程度在这里会有一个UI视图,人可以通过这个视图去解决这两个大的问题,再厉害一点可能连接这两个信息流之间的是AI技术,形成一个信息流的闭环,在这个阶段可能就是所谓的AI Ops,正常来讲是信息收集、加工处理、决策,再信息回流看反馈是什么样的。
3. DataOps 实践
既然把这个阶段叫做 DataOps,肯定是离不开数据的,数据是它的基础,运维的数据是需要按照标准的数仓原则进行建设。右边这张图显示的是整个数据正常的采集、存储最后到加工、应用层的常见步骤,这是从《大数据之路》中拿来的。

常见的运维数据,第一类是维度数据(元数据),服务器、服务器IP是什么,类似于这样的一些静态信息。另一类是度量数据(运行时),也就是指标或者事件类的,还有一类是日志类的。这是运维中最重要的几大类型数据,也是做 DataOps的基础。

这个复杂图是当前我们做 DataOps 的数据架构图,在这里拿出来和大家交流一下,首先左边还是提到刚才的原则,数仓建设的规范。
我们会把数据做一个抽象,上面有好几个大数据平台要管,每个大数据平台会有对应小组的人去负责它的应用那一层运维,所以我们会把重复的,公共的,各个产品都会用到的数据,像机器、指标、日志、监控、报警等的公共信息全部抽取在一起,放在一起去做清洗加工存储。所以会分为公共数据和业务数据两大类型,基于这之上再去构建各种各样的运维场景,像故障自愈、异常检测。

下面就这里的一些场景给大家举些例子。
第一个例子是运维搜索的,简单讲一下知识图谱,运维世界里更多是实体与实体间的关系,用知识图谱的表达方式或者数据的存储形式去表达会更合适一些,尤其是在后面讲到的搜索场景里,有其独特的优势。

基于知识图谱的运维搜索,前面看到一站式的运维体系,这个平台是比较庞大的,比较复杂,那用户进来以后大家都会面临一个问题,总有些人不满意说找不到点,所以我们会有个一站式的搜索入口,你在搜索框里敲想要什么想干什么,比如说有人想做个队列扩容,那只要输入队列,就会把队列相关的实体、动作,包括属性有哪些全部列在这里,那肯定有一个是他想干的。
当然你也可以直接输入这个队列的名称,然后也能给出来这个队列相关的。用起来还是很好用,站点过于庞杂,面对的用户又很多,很难满足所有人的胃口,那让他们方便的来使用这个平台。

基于这个还可以去做 ChatOps,比如说你输一个机器,机器现在的状态怎样,哪个分组,哪个机房,也可以有些基础的基于文档常见问题的问答,或者说让它开一个缺陷出来,类似这样。
当前ChatOps做的还是比较简单一点,还是以查询式的为主,就主要是解决重复的一些简单的答疑类的操作。也就说真正执行命令操作类的基于ChatOps的目前做的还少一点。

下一个场景是关于作业诊断,那么多的用户会来问这个作业跑的有点慢,你来帮我看看怎么了,这是很烦人的一个事情。为了解决这个问题就提供端到端的作业诊断,用户输入作业以后它会去诊断,跟着这个作业全生命周期的流程,我这里讲的所有都是基于说有能力且已经收集好那些信息,而且有了实时性才能去做的。
这里会去看说这个作业分工在哪些机器上,会把相关的机器拉出来,这些机器本身又有没有问题,有了这个以后基本上初级的问题就不用再来问。
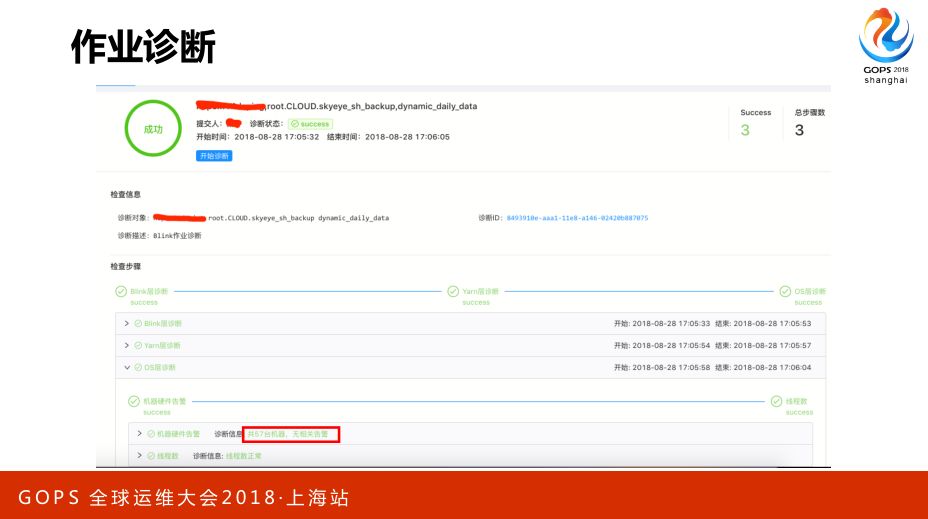
后面再来深入展开一下机器诊断,如果它有fover就给出理由。大家可以看首先机器是不是正常,这就是机器硬件级别的检测,硬件没有问题的话会有一个IO诊断,这边会给出来说分区上的文件,次数是怎么样的,是在读。
还有网络的诊断,针对网络流量满的情况下,哪个进程流量占了多少。这样来解决用户经常问的基于作业运行情况的答疑。

下面介绍两个异常检测的例子,可能这两天下来大家在很多场听了很多,最多的就是基于时序的,所以我们讲点不一样的。
除了时序的还有基于聚类的,适用的场景是有很多大量同质的主机,上面跑的任务都是类似的,而且资源调度器也是比较高效的,能公平的去调度这些作业,理论上这些机器的负载基本上是均衡的,所以可以基于它的CPU、系统的复杂、网络等去做聚类,看看有没有某些机器和别人表现不一样,不一样的话这些机器肯定是有它的各种原因。
根据这个聚类拿到异常组之后再去看它们有没有什么共性,比如说是不是同一天开机的,上面是不是运行同一个作业等等。DBScan的好处是不拘泥于聚类组的数量,如果觉得只要能够发现异常的问题就调的粗犷一点。

第二个是基于日志的日常检测,这个大家讲的可能会稍微少一点。我们更多的是把日志进行模式的提取,模式提取的算法有很多,网上也有很多查到的,比如说文本之间的相似度,就有很多的方式去找日志之间的相似度或者说它们是不是统一类的,有了这个数据之后就可以切面,我们做的时候是把日志的异常检测变成指标类的。

这是日志异常检测的实际例子,大家可以发现说忽然某一类模式的日志变多了,可以看到某个时间段内出现的日志数量达到这么多,也就说大量的作业在某一个时间点出现同类型的日志,很有可能是平台的问题,因为对于我们做平台来讲,更关注的是平台为主的问题,我们可以给它提供这样的渠道去提醒它。
这时候我们可能会怀疑是不是平台有问题了,那可以在日志详情里去看到底是哪类日志,这个例子其实讲的是实时计算的上游那里出了问题。

DataOps 还有一个很大的分支就是运筹优化,可能运维的“运”本来就包含了运筹的意思。运筹优化的例子比较多,多个集群之间容量的均衡,配置的优化等等。

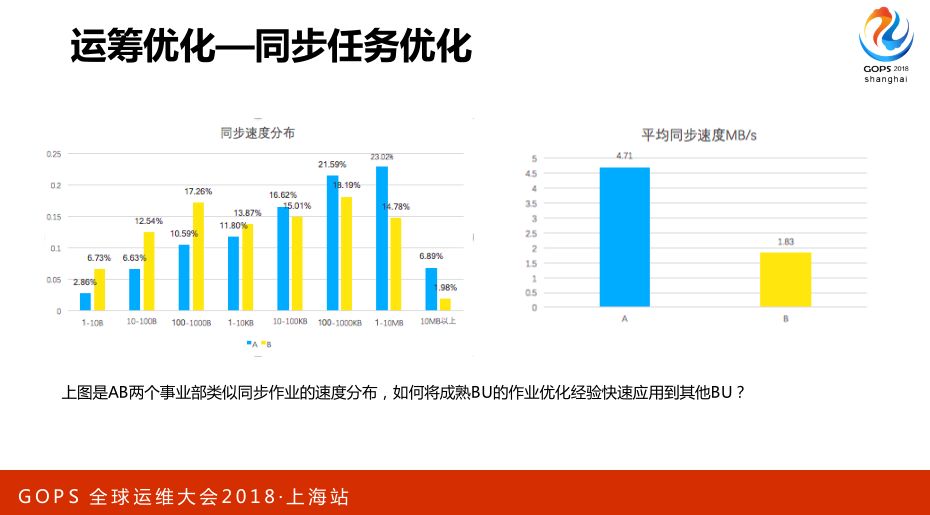
下面举一个例子,关于同步任务的优化,这个例子比较简单,对大家的理解方面、启发方面好理解一点。同步任务就是说在ETL离线处理的第一步,从不同的第一里面把数据统一过来。
我们可以看到这些同步任务A和B是阿里不同的两个BU,写的同步作业的速度完全不一样,ABU平均速度能够达到4兆多,而BBU平均只有1.8几兆,在每个不同的速度区间做一个分布也是完全不一样的,原因是因为ABU的人比较有经验一点或者他们做的时间更久一点。
我们能做的事情是怎么样把ABU的经验快速地复制到BBU,而不需要BBU的开发者再去学一遍,这个场景在大家的工作中也应该是能很容易找到落地点。
我们可以把同步任务的属性拿出来,把它们分为固定属性和可配属性,所谓固定属性是指本身作业固有的属性,对同步任务来讲有源类型,包括它的宿类型,还有一些在运行中可以配置的,比如说并发性、jvm参数是多少等。
固定属性K-means聚类,去找到我们这么多的同步作业到底有多少种类型,找到一个分类,尽可能类型差不多的分在同一类型里面。
完成这个以后再在同一类里面去找到一个比如说单资源情景下的同步速度最高的作业,作为这一类作业的最佳实例,把这个最佳实例的配置应用到同类型里的其他作业,这个问题就解决了,其实是一个自动的聚类、分类,然后再在里面找一个最佳实例。

这是这个配置解决的最后效果,基本上平均速度有7倍的提升,收益还是蛮大的,不用一个个人再去调作业做优化。

4. AIOps 相关
AIOps 我个人认为离它还是蛮远的,但并不是遥不可及,AIOps 只要满足它的一个模式的定义,就可以称之为 AIOps,甚至有一些原来在自动化运维场景就已经实现的了,这是我个人一些浅漏的理解。我的概念里只要是说它能中间利用数据、算码模型做一些决策,且这些决策能够自动的去应用到线长,形成这样一个闭环,不需要人干预的,我认为这个场景就可以称之为AIOps。
4.1 AIOps的监控自愈
最头疼的是半夜收到告警、周末收到告警、看电影时收到告警,这里面把它用AI Ops的框架再去梳理一下,提升它的效果。
主要是三大部分:
第一部分是感知,怎么去感知到异常事件的发生,如果做监控自愈的话来源就比较简单
第二部分是决策,做实时的决策处理。
第三部分是自愈,同时还要再去关注一下是否都解决了
作业平台推给流程平台,流程平台中会就人介入做一个审核,可能有些重要的机器是不能重启的,或者在某些告警情况下不适合做下线,这可以分阶段去做。

4.2 AIOps 硬件自愈
整个计算平台物理机这块非常多,如果人去做硬件故障发现、保修,至少要投一个人全职在这件事情上。在这些服务器上会装上一个系统,它会去采集硬件故障判断相关的例子,采集完以后通过SLS数据通道,再通过流计算做分析聚合,最后放到OLAP里面,结合它原有的模型去做一个判断,说这台机器是不是有问题了,同时也会受业务安全模型的制约。
最后它会产生动作,会把这个动作扔到事件中心,就产生下线或者重启等。也正是基于这样一套系统可以帮我们把这方面的人力省下来,一年处理20万次自愈事件,服务器可用率99%以上。

4.3 AIOps 的资源优化
怎么给集群的作业划分quota组最合理?首先要建立资源划分的满意度模型,因为你不可能让所谓的AI模块自己去判断说这用户用的爽不爽,这不可能的。

那资源满意度模型可以根据自己的业务特点去建,一套综合评价体系主要包含用户资源抢占、等待分配时间、资源满足率等,用Tdata时序异常检测模型跟踪用户满意度变化情况。有满意度模型且能够发现异常以后,那就去做智能的资源调配的事情,选一个模型对未来一周的用户组的资源做一个预测,当然这方面的模型比较多我也不详细地展开了。

最后基于每个配额组未来一周的资源消耗预测值结合该配额组的历史用户满意度数据和所在用户等级的服务SLA,根据这三项结合,最后给出这个资源组配置的推荐值。

当然这个值过去以后还会形成一个闭环,因为用户满意度的异常检测是实时一直在线上跑的,如果忽然发现某个用户不满意的话会及时调整。

责任编辑:Erin

 评论表单加载中...
评论表单加载中...




