| 摘要:在NVIDIA GTC2020大会上,NVIDIA正式发布了7nm安培GPU,号称是8代GPU史上最大的性能飞跃!黄仁勋从厨房里面烤出了史上最大GPU。 |
在NVIDIA GTC2020大会上,NVIDIA正式发布了7nm安培GPU,号称是8代GPU史上最大的性能飞跃!黄仁勋从厨房里面烤出了史上最大GPU。

A100:全球最大7nm处理器,首款安培架构GPU
来了,终于来了!全球最大7nm处理器、英伟达最高机密、首款安培架构 GPU,NVIDIA A100,终于出现了!

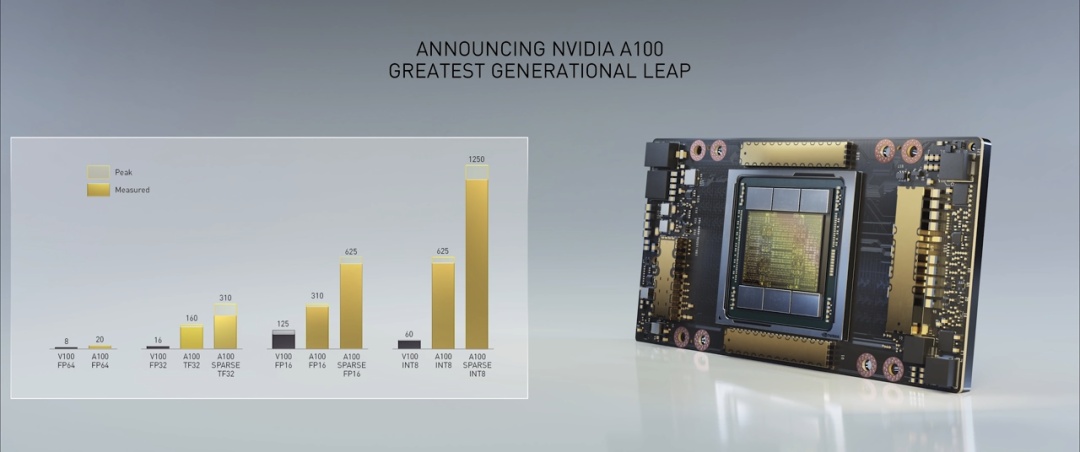
这次黄仁勋带来的NVIDIA A100数据中心GPU,无论是在数据分析、训练还是推理方面,都能大幅提升数据分析、训练或推理应用的吞吐量,整体性能相较于前一代产品直接提高了20倍!
以BERT算法为例,相比T00,A100在训练上提升6倍,在推理上直接提升7倍表现。
A100 GPU 包含超过 540 亿个晶体管,使其成为世界上最大的 7nm处理器。搭配 HBM2 显存,面积 826 平方毫米,60GB/s NV LINK,现已全面投入生产并交付全球客户。
A100 集成了英伟达的几项最新的计算技术,凭借其第三代tensor核心、多实例GPU技术、稀疏度加速以及第三代NVLink和NVSwitch互连技术,可提供每秒1.5兆字节的带宽。它基于NVIDIA全新的Ampere架构,在性能上实现了史上最大飞跃,尤其适用于深度学习和某些特定的 HPC 任务。
甚至第三代 NVIDIA NVLink 互联技术还可以实现让多个 A100 GPU进行合体,组成一个巨型的 GPU 来执行更大规模的训练任务。
DGX A100是一个集成的AI系统,在单个节点上具有5 petaflops的性能,并附带完全加速的软件堆栈。此外,它还可以在全球领先的系统制造商HGX A100超大规模数据中心加速器中使用。
据了解,美国、德国的多个实验室及超算中心已经开始使用 A100 作为超算解决方案。
NVIDIA EGX A100融合加速器,将NVIDIA Ampere GPU和NVIDIA Mellanox ConnectX-6 DX SmartNIC结合在一起,将安全计算带到边缘。黄仁勋还宣布,宝马公司已经选择了NVIDIA Isaac机器人平台用于工厂物流。
同时,黄仁勋还再次提到了实现AI性能新里程碑的Volta Tensor Core GPU,基于Volta的Tesla V100创造了单块处理器最快速度记录。

现场演示更快更懂你的推荐系统、可以互动的会话AI
这些新技术可以随意组合,从而能够让NVIDIA A100在各种苛刻计算负载下都能游刃有余,成为黄金右脚。在科学仿真、会话AI、推荐系统、基因组学、高性能数据分析、地震建模和财务预测等应用场景都有用武之地。
光说不练不过瘾,黄仁勋还亲自示范了推荐系统和会话AI。
更快更懂你的Merlin
你如果分手了,可能会在朋友圈看到世纪佳缘的广告,对,现代的推荐系统就是这么精准,它会根据你的浏览历史或者购买习惯,为你推荐所需的产品或服务。
的确,推荐系统已经无处不在了。黄仁勋认为它是“当今世界上最重要的人工智能模型” ,“驱动着互联网的绝大多数经济引擎”,而英伟达的Merlin正是你需要的推荐系统的应用框架。
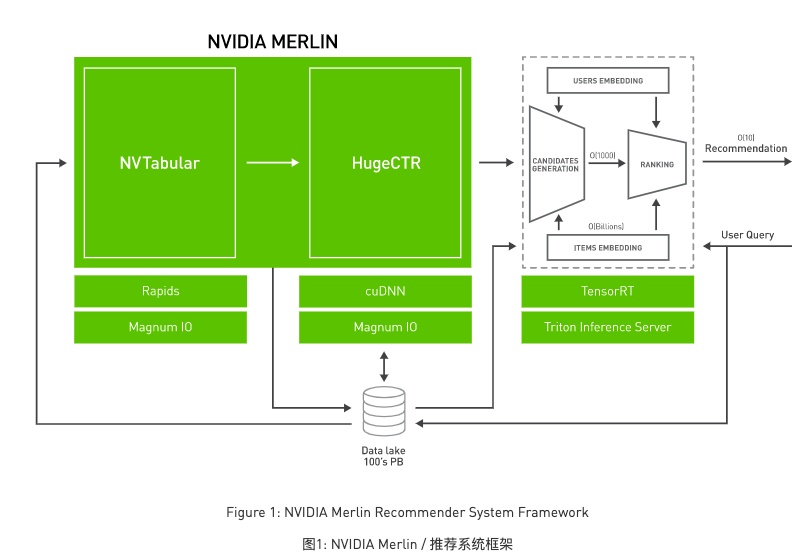
NvTabular 通过GPU加速特征转换和预处理,自动完成TB级数据的分区和扩展,原来需要几个小时的高维数据预处理,现在可能3分钟就搞定!
HugeCTR 是一个深层的神经网络训练框架,能够跨多个 GPU 和节点进行分布式训练,以获得最大的性能。
Nvidia TritonTM Inference Server 和 NVIDIA TensorRTTM 加速了GPU 的特征转换和神经网络执行的推理速度。

双簧大师、对话鬼才:Jarvis
黄仁勋再次推销起自家的会话AI:Jarvis。
英伟达为了展示Jarvis的能力,特意打造了一个「对口型人脸模型」以及一个聊天机器人Misty。
英伟达一名工程师兼Rapper来了一段黑怕,人脸模型就根据声音来对口型。相比正常说话,黑怕的速度更快,词汇更加复杂。下面的动图看得出,Jarvis毫无假唱痕迹。

而一个雨滴型的聊天机器人Misty就更有意思了。她可以根据不同的聊天内容做出一些好玩的特效。比如你问她世界上最冷的城市,她不仅能够给出准确的答案,还会用动画特效来显示出寒冷之意。而讲到闪电,除了讲解闪电的基本常识外,还显示了一个被雷劈的效果,看着挺疼的…

Spark工程师的福音
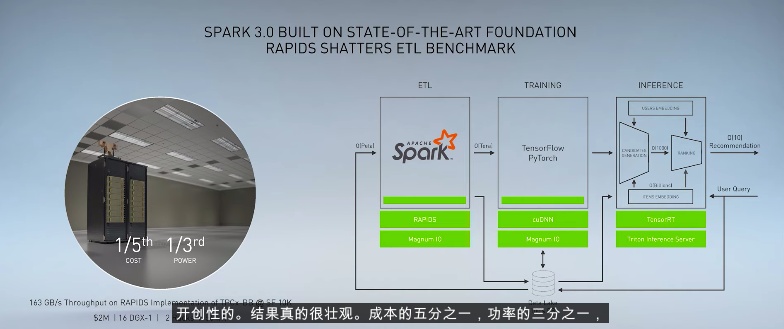
黄仁勋还宣布 Apache Spark 3.0中将支持GPU加速,用Apache Spark 从事数据分析和机器学习的人员来说无疑是天大的福音。
Spark之前虽然可以实现分布式计算,但调度CPU也会耗费巨大的资源,之前如果每秒处理17GB的数据,你需要价值100万美元的戴尔服务器。

而在Spark 3.0中有了英伟达最新GPU的加速,直接成本只需要原来的1/5,而功耗更是减少到原来的1/3,用黄仁勋的话来说,太壮观了!
疫情期间AI治病救人
黄仁勋首先讲述了在英伟达和Mellanox共同打造的数据中心加速计算的未来。
疫情当前,首要的就是治病救人。
英伟达与Plotly合作,进行实时感染率的分析。「在Oak Ridge国家实验室和Scripps的帮助下,我们每天能够筛选十亿种药物。」
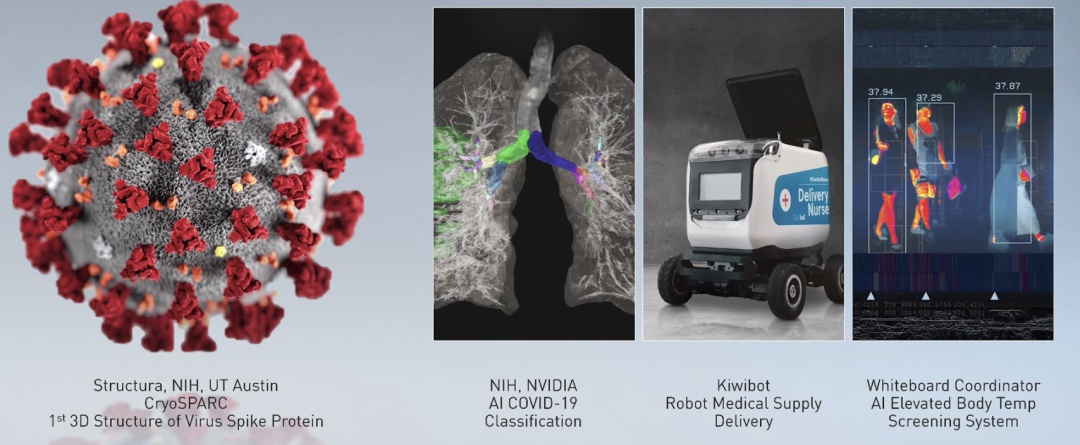
NIH和NVIDIA建立了一个AI模型来对COVID-19进行分类。Kiwibot建造了一个机器人来自动提供医疗供应。医疗领域深度学习创企Whiteboard Coordinator构建了一个AI系统自动检测体温。
「研究人员正在运用NVIDIA的加速计算来挽救生命。」
除了医疗AI,英伟达的合作伙伴还包括各行各业的领军者。

Oxia Palus:用AI修复名画

英伟达DLSS 2.0,AI渲染的里程碑
实时光线追踪,一直是游戏发烧友们梦想中的效果。
在Part2,黄仁勋介绍了NVIDIA RTX如何将计算机图形学带入一个新时代,该技术将光线追踪(ray tracing)和AI相结合,创造出令人眼花缭乱的视觉效果。
2018年温哥华的Sigraph上,英伟达RTX正式发布,是计算机图形的一个里程碑。
而英伟达团队在过去的三年中一直在试图解决一个问题,就是ray tracing速度不够快的问题。
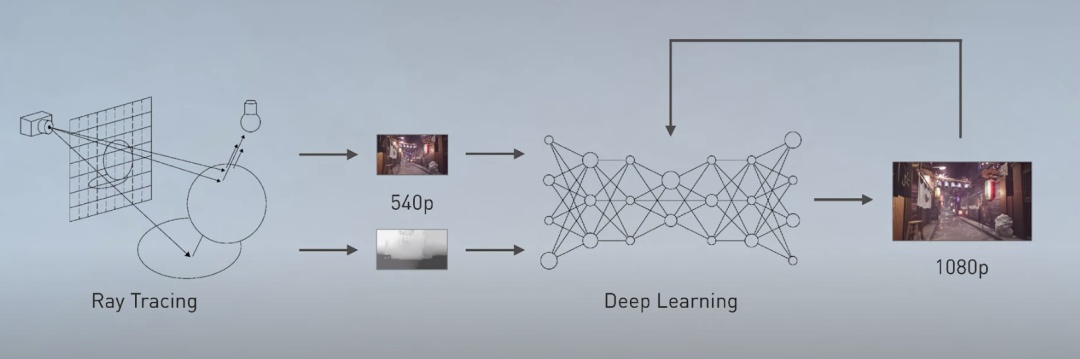
于是,今年3月份发布的NVIDIA 的DLSS 2.0(deep learning super sampling深度学习超级采样)应运而生。
DLSS2.0是一个改进版的深度学习神经网络,基于GeForce RTX GPU的Tensor Cores,实现了实时光影追踪,它可以使用AI将低分辨率图像放大到优于原生1080p的画质。
「我们目的是让AI认识到真正高清晰度的画面是什么样的,通过不同场景的训练,神经网络可以预测出下一帧高清画面的样子」。


使用DLSS2.0深度学习超分辨率从720p渲染到1080p比原生的1080p画面还要更加优质
这是一个意义重大的飞跃!
将RTX融入到著名游戏Minecraft 游戏当中,灯光效果相当惊人。

有没有RTX,前后效果相差巨大。

总结说来,这次厨房发布会还是干货满满,不再像19年的那次「三无」发布会。
新的 NVIDIA Ampere 架构、 NVIDIA A100、 GPU 加速的Spark 3.0、 Merlin、 Jarvis -- RTX Server、 DGX A100、 Mellanox connectx 6 DX SmartNIC、 HGX A100、 EGX A100,医疗AI、自动驾驶、数据中心,英伟达已经开始向AI领域全面进军。
一个属于加速计算的未来,你准备好了吗?
责任编辑:张华

 评论表单加载中...
评论表单加载中...




