| 摘要:重复数据删除技术在海量存储系统中很重要,近年来也引起了学术界和工业界越来越多的关注。一般来说,重复数据删除是一类旨在最小化文件之间(inter-file Level)的冗余和重复 (Duplication&Redundancy)的无损压缩算法 (Lossless Data CompressionAlgorithms)。重复数据删除的优点是可以相应地减少网络中的数据传输量。 |
重复数据删除技术在海量存储系统中很重要,近年来也引起了学术界和工业界越来越多的关注。一般来说,重复数据删除是一类旨在最小化文件之间(inter-file Level)的冗余和重复 (Duplication&Redundancy)的无损压缩算法 (Lossless Data CompressionAlgorithms)。重复数据删除的优点是可以相应地减少网络中的数据传输量。
1.重复数据删除的技术桃战
根据调研结果,当前绝大多数的重复数据删除算法都工作在二进制数据层次上(Binary Data Level)。在此基础上,通常使用一些数据切分箕法,如以整个文件为切分粒度(Whole File Chunking),固定大小的数据切分 (Fixed Size Diciding),或某些Hash函数 (如RabinFingerprinting算法),将每一个带归档的文件切分成若干相互不重叠的数据片段,并把这些数据片段作为逻辑单位进行后续处理和存储操作。在这些数据片段中,只有不重复的数据片段才真正存储到存储设备中,而其他的重复数据片段只需要记录其lD和相应的依赖文件的对应关系即可。但是当前带重复数据删除的存储系统仍然有若干的技术挑战氶待解决。如果我们简单她使用上述文件切分算法,则两个只有少许差别的文件有可能被切分成具有很大差异的数据片段。例如,一个典型的HTML文件由若干的标签 分割为具有语义的数据块。如果使用现在的数据切分算法,如RabinFingerprinting来切分该文件,则切分点[45]有可能在一个标签的内部,这样就会造成与该数 据块相关联的语义信息的丢失。
另外,因为切分出来的数据片段常常是变长的(Variable Sized),把它们直接存储到磁盘设备中会产生大最的磁盘碎片,并带来高比例的随机数据访问(Random Disk Accesses),这是非常低效的[47]。更糟糕的是,。由于用现有方法切分出来的数据片段往往是没有语义含义的,如何分布这些数据片段,特别是在大规模分布式存储系统中,如何把这些数据片段有效分布到存储设备上去,以方便以后的数据管理和文件检索、查找,也是一个需要着重考虑的问题。例如,将这些数据片段随机地分布到存储设备中去,用户通过查询工具需要进行文件访问或检索时,则存储系统需要首先检索文件涉及的数据片段所处的位置 (可能随机分布在整个系统的各存储设备中),然后把这些文件重新组织起来,再判断这些文件的内容是否符合查询语句的要求。这个过程的代价很大,常常使很多较高层应用程序的性能明显降低[46]。
2·ADMAD
应用驱动、元数据相关的重复数据删除(Application-DrivenMetadataAwareDe-duplication,ADMAD),其主要思路是通过利用I/O路径上不同层次上的元数据信息,如待归档文件的文件类型、文件格式、应用类型和文件系统元数据等,来指导数据切分算法将文件划分为相对于当前其他算法更有语义含义的数据片段 (moreMeaningful data Chunks,MC)。MC是变长的、自识别的和自描述的逻辑存储单位。归档文件的元数据信息分为以下三类:(1)应用元数据,如文件类型、件格式、应用软件信息等:(2)应用或用户的标记,如用于描述博客、图片或多媒体文件特性的各种标记:(3)文件系统级元数据,如目录条目、文件的inode信息等。
ADMAD的主要目标是最大限度地减少文件之间的重复和冗余数据,但由于MC可能具有不同长度和可变长度,把它们 (如以文件的形式)直接存储到磁盘设备中会产生很多碎片,并带来大量的随机访问,会大大降低数据访问性能。所以ADMAD设计相应的算法和流程,进一步将MC封装成定长的数据对象 (Object),后者是存储设备上的物理存储单位,以便充分利用磁盘设备“大读大写”*的特性,提高I/O性能。需要说明的是,一个数据对象可能包含若干个、一个或部分的MC。实验表明,ADMAD 的性能跟当前主流的存储架构是相当的。
ADMAD主要由两个部分组成,即解决以下两个问题:(l)如何把艾件切分成数据片段在初步实现中,使用文件类型和文件格式作为主要的元数据信息,来指导文件的切分同时使用二进制切分算法Rabin Fingerprinting.(2)如何把逻辑的MC高效地存储到物理设备中?ADMAD通过把变长的MC封装成为合适长度的定长数据对象 (数据对象的长度可根据使用的文件系统及应用进行确定)。数据对象是磁盘设备上进行实际存储的基本单位。通过上述两种方法,可以在尽可能地减少文件之间的重复和冗余数据的同时,简化数据管理,并避免对存储设备的碎片或小文件进行随机读/写。数据对象最终存储到存储节点中,存储节点由通用组件构成,并在其中部署ADMAD的相关软件后台进程 。
以电子邮件归档存储系统为例。假定邮件服务系统中有两个邮件分别由Alice和Bob收到,两个邮件的发送者和附件相同。对每个邮件进行ADMAD文件划分时,具有相同发送者片段和相同附件片段的数据内容被切分成一个语义数据片段,只需要保存其中的一份即可。进一步将逻辑的数据片段存储封装成数据对象时,由于Rabin Fingerprinting等算法可以捕获到二进制层次上的重复,所以若两个数据对象具有相同的内容(如都由全O比特串组成)则可进一步进行重复数据删除,只存储不重复的对象。图4.3展示了上述过程,并说明了在归档存储系统中数据组织的层次
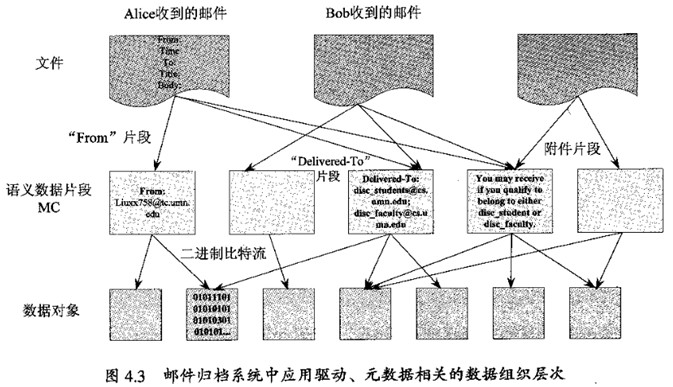
以上述例子可以看出,ADMAD的主要优点有两个方面:能有效的发现文件之间的重复或相似部分,最大限度地消除重复;能再存储级实现数据访问和查找管理最佳化。例如,要在邮件档案系统中搜索某人的邮件,ADMAD只需要检查MC的相应部分,查看其是否与请求的查询匹配,而现有的方法加载全部文件并对其内容进行扫描。
责任编辑:GOCN
 评论表单加载中...
评论表单加载中...




