| 摘要:针对重复数据删除系统设计了一种存储流水线,实现CPU、I/O及网络通信任务的边界重叠。它把整个I/O路径分成若干级 (stage)且串联在一起,一级的输出是下一级的输入。请求从一端迸入,顺序经过各级,从另一端出去。这些级的执行是相互重叠的,是并行的或者说是时间片的风格。每一级与其他级并行操作,尽管不同的请求会改进系统的吞吐最,吞吐量大小是由一个请求多久脱离该流水线所决定的。存储流水线对上层的应用和程序员来说是透明的。 |
针对重复数据删除系统设计了一种存储流水线,实现CPU、I/O及网络通信任务的边界重叠。它把整个I/O路径分成若干级 (stage)且串联在一起,一级的输出是下一级的输入。请求从一端迸入,顺序经过各级,从另一端出去。这些级的执行是相互重叠的,是并行的或者说是时间片的风格。每一级与其他级并行操作,尽管不同的请求会改进系统的吞吐最,吞吐量大小是由一个请求多久脱离该流水线所决定的。存储流水线对上层的应用和程序员来说是透明的。
设计一个有效率的存储流水线必须解决两个关键技术问题。一个关键技术问题是级处理时间,也就是将请求沿着流水线移动一步所需的时间,它受限于最慢的流水级,一个存储流水线的主要设计目标是平衡每个流水级的长度。也就是说,要尽可能地等分整个 I/O路径到均衡的流水级中。另一个关键技术问题是各个流水级相互关联,它们必须准各好以便同时发生。在相邻流水级之间的通信及缓存机制应该是充足的,一定要确保级间数据和消息的传递。特别是在去重系统中,处理时间是不规律的,数据项沿着流水线不停地创建成销毁,所以应设计某些专用的缓存管理方案。
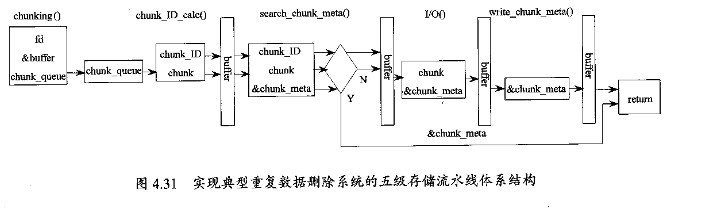
图4.31所示为实现典型重复数据删除存储系统的五级存储流水线体系结构。在chunkingO级将每个文件划分成可归档的不定长且互不重叠的数据片段:chunk_ID_calcO级为每个数据片段生成一个全局唯一的标志符,通常依据数据片段的内容使用诸如MD5和SHA这样的加密Hash函数获得。鉴于加密Hash函数的计算限制,提出一个并行chunk标志符计算算法来加速这一过程:search_chunk_metaO级查找从chunk标志符到chunk元数据的索引映射表 (如文件中的偏移最、在存储设备中的位置、chunk大小)来确认该数据片段是否存在,只有唯一的一份数据片段实际存储在存储设备中;I/OO级完成数据片段内容的实际存储动作,由宿主 OS或文件系统提供的cache机制可以用来加速异步模式I/O性能:Write_chunk_metaO 级将实际存储的数据片段的元数据插入到相应的索引表记录中。在大规模去重存储系统中,索引表的大小会急剧增加,内存容量可能不够。这些情况下,应当设计特定的数据结构来降低查找及更新的复杂性。
责任编辑:GOCN
 评论表单加载中...
评论表单加载中...




