| 摘要:本文是针对在基于主机的网络应用程序中采用通用CPU的相关优势及陷阱进行深入挖掘分析,并就当前被用于基于主机的网络以提供更好性价比的不同服务器网络硬件技术进行探讨的系列文章的第二部分。在本系列文章的第一部分中,我们主要关注了基于主机的网络的硬件加速的潜在问题及重要性。而在本文中,我们将探讨当前被用于这类智能服务器适配器的三大基本技术,并将就提供最佳性价比的基于主机的网络的解决方案提供相应的指导和建议。 |
对于那些部署或评估基于主机的网络应用程序的数据中心运营商们而言,他们将面临如何成本有效地采用基于COTS(商用现成品或技术,Commercial-off-the-shelf)的服务器平台将其企业网络规模化扩展到10,25,40乃至50GbE网络的挑战。正如我们在前一部分的文章中所介绍的那样,诸如vSwitches这样基于主机的网络功能,完全是以软件的形式部署实现的,而由于在数据面板处理过程中,价格高昂的x86 CPU内核相当耗能,其在10GbE和更高速度的网络中无疑是成本昂贵且低效的。故而,本文特别针对各种基于主机的联网方式的性价比进行了比较。
涉及到纯软件实施部署的根本问题是:当涉及到数据包时,隧道和数据流处理时,x86架构的能力与基于主机的联网处理的基本要素根本不匹配。这是因为x86及其他针对计算服务器的通用型处理体系结构是用于在操作系统环境中运行复杂和相对长时间运行的应用程序,进行了设计优化。这种方法非常适合服务器应用程序,但当涉及到基于主机的网络时,它不一定是最好的策略。为了更好的了解x86服务器这些优先事项,我们建议您参考下图所示的Sandy Bridge装置的芯片级视图。

图1:英特尔x86:优化的服务器,而不是基于主机的网络。
在传统的操作系统环境下运行优化的通用计算应用程序的需要,为CPU处理器架构带来了大量的复杂化。x86内核加载的功能包括了拥有诸如相当漫长而复杂的超标量处理管道、推测执行和分支预测,大的缓存和MMU以支持虚拟内存等的诸多功能,所有这些功能都造成了每个内核的大型芯片面积(die area)。需要大规模的L3缓存以支持非常大的程序和外部存储器中的数据集,但基于主机的网络数据路径程序和数据都比较小,在一个单独的配置中并不需要L3。同样,在x86的图形处理和浮点单元也不需要数据路径处理。由于这些服务器类的功能极大地推动了处理器芯片的规模,却并没有增加基于主机的网络功能的工作输出,他们极大地降低了整体解决方案的性价比。
事实上,将x86应用于基于主机的网络就像是试图用柴火来牵引法拉利一样:这根本就不是可以用来完成工作的正确工具,其成本太过于昂贵而不能实现。这个问题目前已得到了广泛的认可,而自然反应一直在追求纯软件的优化。诸如像数据面开发工具套件( Data Plane Development Kit,DPDK)这样的技术旨在通过提高缓存利用率,并消除中断处理的能耗来改善x86 CPU在网络应用程序的性能。同时通过减少处理器闲置空转的百分比提供适度的改善,这种方法不能克服上述基本架构的限制,因此进一步的有效的改进将是相当有限的。
x86基于软件的替代方案
在x86 CPU上基于主机的网络软件提供良好的性价比的失败为追求成本有效地规模化扩展到10,25,40,50和100GbE线路速率的替代解决方案带来了积极的动力。而其中一款替代方案方法便是配备了MIPS- 或基于ARM多核系统单芯片(System-on-a-chip,SoC)技术的智能服务器适配器。在该模型中,SoC部署在基于主机的网络数据路径,整个软件完全运行在的SoC处理核心。这样做虽然卸载了服务器,但这并不改变基本的处理范式:SoC的方法受到与x86 相同的基本架构局限。这是因为这些SoC设备的架构是首先是针对服务器市场优化的,然后才是被用于服务器适配器,所以上述适用于x86的效率低下的问题在这里依然存在。这种方法只是对处理资源的一种再分配,对提高整体解决方案的效率和性价比没有太大的效果。其缺点是显而易见的,基于SoC的服务器适配器根本很难实现线速,而在当前的网络所部署的最大数据包大小则是20Gbps。
另一个经常被讨论的替代方案也是十分相似的:利用现场可编程门阵列FPGA(Field-Programmable Gate Array)。最近有文章介绍了FPGA对于涉及到在数据中心网页搜索特定算法的相关的加速的好处(1)。甚至还有人建议针对基于主机的网络的数据面处理采用同样的方式。但对于基于主机的网络采用FPGA的效率和成本效益尚未得到证实,而基于下文所指出的各种原因,其获得广泛采用似乎不大可能。
FPGA适合于重复的,细粒度性质的明确的任务,如图像和信号处理、压缩/解压缩、加密,等等。它们通常比在通用处理器上运行的软件能够更高效地执行这些任务。然而,对于那些复杂的、可变的和不规则的处理任务,需要进行分组处理的,FPGA处理起来则是不佳的。所需要的功能,如分支、位操作、封装和过滤等,会为FPGA在实现网络数据路径时造成很大的困难。
此外,较之标准的ASIC技术,FPGA产生一个巨大的面积效率(area-efficiency)的损失,其在非常具体的用例之外很难克服。在FPGA中的可编程互连基础设施消耗大量的芯片面积,导致较之基于ASIC的设计,会产生单位面积大约20-30倍的低效逻辑网关,和12倍多的动态功率等效功能(2)。鉴于服务器适配器的芯片面积的上限是由成本和功耗的共同点所驱动,FPGA是在性能效率方面具有显著劣势。
此外,FPGA中的主要好处之一,便是通过重新编程适应功能的能力,其往往是在相当有限的实践中。显著更改数据路径可能不适合或在目标设备的路径,或者可能无法达到同一目标的工作频率。此外,FPGA的一般程序使用深奥的硬件描述语言,如Verilog或VHDL,并且需要具备良好性能的手工编码。通过利用C语言的OpenCL和其他方法支持的FPGA编程改进能够带来简化的开发,但只有在牺牲更高的效率,并以进一步削弱性价比为代价。
我们只需要回顾历史,看看FPGA一直被用于网络数据路径的利基应用。通常情况下,他们作为一个权宜之计,直到更多高效专用解决方案变得可用。事实上,FPGA的使用常常是作为一个产品存在差距的指示器,而如果差距是在一个有着足够的市场规模的领域,专用解决方案将不可避免地被开发。
基于所有上述原因,搭载多核SoC或FPGA的智能服务器适配器显然缺乏适应当今和未来的基于主机的网络应用程序所需的伸缩性和可扩展性。当然,这是一个我们所熟悉的主题。而业界也在不断试图为新应用程序重新使用现有技术,其已被证明是有必要的,以新的和专门构建的技术适应新的网络加速效率规模和要求。
专用解决方案演进成为主流
当可用的解决方案无法满足新兴的和令人信服的用例的需要,特制的解决方案就将不可避免地演变作为补充,有时甚至会取代他们。在上世纪90年代, IP路由器就已经被部署在了所有通用CPU的软件上了,但由于互联网带动流量的增长,所导致的更高的性能和规模的爆炸性需求,网络处理器诞生了。 ATM演变为专门构建的和有针对性的技术预期,部分以适应融合多种通信流量类型的需求。 MPLS演变的下一步是作为一个扩展的以太网,纳入最佳ATM作为一款卓越的解决方案,扩展基于2层和第3层的VPN。这些技术的初步实现往往发生在FPGA中,但很快,ASSP被开发,可以提供更好的性价比,以执行这些功能,导致其成为主流。
类似的发展演变也在InfiniBand和RoCE发生。RoCE适配器是专为使用率很低的低延迟和大规模数据传输的CPU而打造的。由于该解决方案提供了优越的性价比和可扩展性,它能够克服那些已经被视为显著的障碍:使用InfiniBand传输层和IBTA定义相对于TCP / IP和传统套接字接口更熟悉。它的优势占了上风,并逐步增长,而RoCE 目前已经更新到第2版,增加了对路由和部署跨3层网络的支持。虽然RoCE 最初实施主要是在服务器的软件上,其处理负担则是非常高的,这推动了具体解决方案以服务器适配器的ASSP形式支持RoCE 直接从硬件卸载,现在成为主流。
特制的技术从专门到主流部署的发展演变作为更具成本效益的方法,意味着适应不断变化的需求,演化示图见下图2。除了IP / ATM / MPLS和RoCE,图中还展示出了专用3D图形技术集成到现在已经在电脑普及,提供了最初软件在服务器上实现的功能的主流的基于GPU的产品然后转移到一个专用的加速器的演变的另一个很好的例子,最后以GPU适配器的形式成为主流应用。同样的进化过程中也开始在基于主机的网络使用情况中出现,并产生了一个新的专用技术:网络流处理器(NFP)。
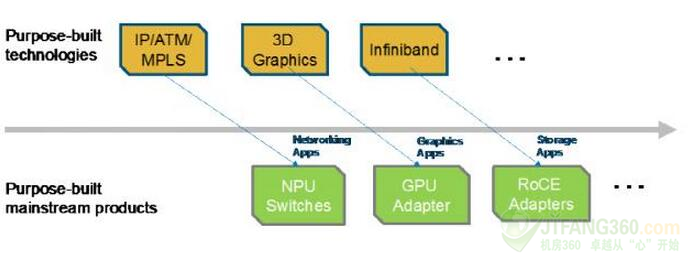
图2:专用目的构建的技术找到成为主流部署的方式。
网络流处理器:专为基于主机的网络构建的克服多核SoC和FPGA的性能和可扩展性限制需要解决造成这些局限性的根本原因。基于NFP的智能服务器适配器能够从10Gbps有效扩展到100Gbps的吞吐量,提供超过现有基于软件的解决方案,带来一个数量级的性能提升。图3显示出了用于一个公共的基于主机的网络数据面应用程序的吞吐量比较,开源的vSwitch(OVS)。如图所示,对于等量的x86 CPU资源(单核的x86),基于NFP的智能服务器适配器在数据包吞吐量方面提供超过20倍的改善提高,从而极大地提高了性价比。
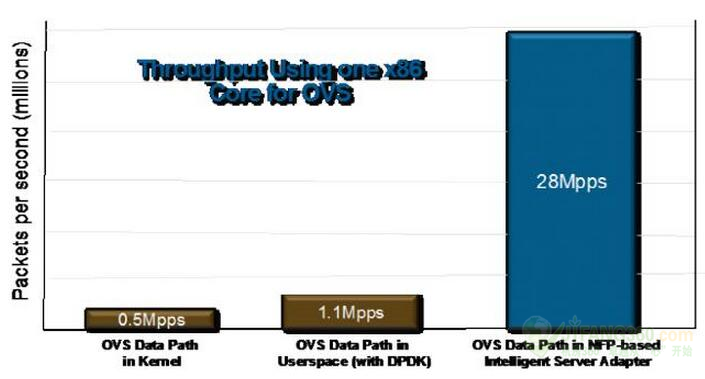
图3:使用基于NFP的智能服务器适配器的基于主机的网络性能。
虽然我们预计其他基于MSOC或FPGA的智能服务器适配器能够至少在性价比方面能有所改善,但并不是所有的这种适配器都是一样的。在本系列文章的第三部分,也即最后一篇文章中,我们将为您概述在评估基于主机的网络应用的智能服务器适配器时,会对您有所帮助的几个重要特征。
索引:
(1)微软《大型数据中心服务的加速重配置结构》
(2)《FPGA和ASIC之间的差距测量》伊恩久远和乔纳森玫瑰,,多伦多大学电气与计算机工程系 Ian Kuon和Jonathan Rose合著
关于作者
本文作者Nick Tausanovitch拥有电子和网络相关行业超过25年的经验,从业的范围涵盖了从FPGA和芯片设计到系统架构和产品营销。Nick目前是Netronome公司解决方案架构资深总监,他主要负责该公司的数据中心应用程序企业智能服务器适配器产品。此前,他曾负责Broadcom公司的高端网络处理器产品线。在此之前,Nick曾担任IDT公司的电子设计主管,在那里他开发了TCAMs和搜索引擎算法。并曾在Nortel公司担任过系统架构师,负责开发交换机、路由器和网络处理器。Nick持有罗切斯特大学的电气工程科学学士学位及纽约大学理工学院电气工程硕士学位。
责任编辑:余芯
 评论表单加载中...
评论表单加载中...




