| 摘要:本文概述了AI数据中心布线方面的挑战和机遇,旨在帮助自建AI集群的数据中心企业找到AI集群的理想布线方式。 |
几十年来,人工智能(AI)的威胁一直是科幻小说不变的主题。荧幕反派角色,比如《黑客帝国》中的机器人,都站在了人类的对立面,迫使人类必须克服这些技术带来的威胁。对人工智能(AI)和机器学习(ML)在实际应用中的潜力,人们的兴趣有增无减,而且新的应用层出不穷。最近,ChatGPT引起了广大公众对AI可以做什么的极大兴趣,也引发了人们关于AI将如何影响工作和学习性质的讨论。全球已有数百万用户在使用ChatGPT、Bard和其他AI接口,与AI进行交互。但大多数用户还没有意识到,他们与AI助手进行的交流实际上离不开世界各地大型数据中心的支持。
本文概述了AI数据中心布线方面的挑战和机遇,旨在帮助自建AI集群的数据中心企业找到AI集群的理想布线方式。
二、高效训练
许多企业正投资于数据中心内的AI集群,开始构建、训练并完善AI模型,以适应自身的经营战略。这些AI内核由一个又一个机架内的GPU(图形处理单元)组成。GPU提供了AI模型对算法进行详尽训练所需的强大并行处理能力。GPU芯片最擅长并行处理的,非常适合AI。如图1为CPU和GPU在智算中心的作用。
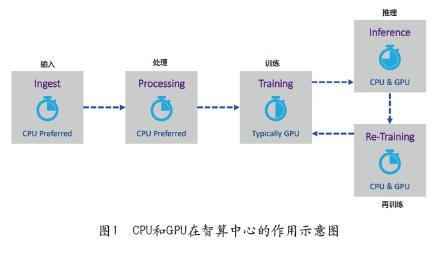
通过导入数据集,训练、推理等过程,AI会分析数据并进行理解。比如,基于猫有别于狗的常见特征进行训练,确定图中是一只猫还是一只狗。接着,生成式AI会处理这些数据,创建出全新的图像或文本。
虽然这种“智能”处理引起了世界各地个人、政府和企业的极大兴趣,但开发一个有用的AI系统既费钱又耗能,因为它需要大量的数据用于训练。这些用于训练和运行AI的模型是单台机器所无法承受的,AI模型的增长,以PetaFLOPS(FLOP为浮点运算单位)为单位。许多服务器和机架上的多个GPU一起工作才能处理这些大模型,在数据中心内维护这些计算集群协同工作处理数据。这些GPU必须通过高速连接才能完成AI的工作。特定机架空间能配备多少GPU受到了GPU的能耗和散热容量的限制,因此必须优化物理布局,并最大限度地降低链路延迟。
三、AI集群对于数据中心的挑战
AI是当前和未来数据中心增长的主要驱动力。AI包含以下三个方面:
1)在训练期间,大量数据被输入算法,用于学习。
2)然后,推理AI获取信息并进行分析。
3)生成式AI是最令人兴奋的环节,因为通过简单的提示,算法可以输出以前从未创建过的文本或图像。
智算中心的挑战有三个:提高带宽;降低延时;降低功耗。因此基于多模光纤的400G和800G技术将会得到大量采用。
在网络方面的挑战:GPU计算集群需要大量的服务器间连接,但由于功耗和热量的限制,每个机架不得不减少服务器的数量。这样智算中心比传统数据中心拥有更多的机架间布线,因为设备间的大吞吐量需求,需要400G以上的带宽支持,铜缆应用减少,光纤光缆应用大幅度增加。
在能耗方面的挑战:面向AI的机架需要大约40千瓦才能为GPU服务器供电。这一功率比典型服务器机架功率高四五倍,这样按较低功率要求构建的数据中心将需要升级或者建立专门的GPU高密度机架区域。
在NVIDIA描绘的理想场景中,AI集群中的所有GPU服务器将紧密结合在一起。与高性能计算一样,AI机器学习算法对链路延迟极为敏感。NVIDIA的内部统计,运行大型训练模型有30%的时间花在网络延迟上,70%的时间花在计算上。由于训练一个大模型的成本可能高达1000万美元,因此这种网络延迟时间代表着一笔巨大的费用。即使是节省50纳秒延迟或10米光纤的线路距离,效果也非常明显。对于时间敏感性的推理数据交换更需要缩短链路距离;通常AI集群的链路都限制在100米范围内。
四、智算中心网络架构
几乎所有现代数据中心,尤其是超大规模数据中心,使用的都是折叠式CLOS架构,也称为叶脊架构。数据中心的所有叶交换机(LEAF)都连接到所有脊交换机(SPINE)。在主机房,服务器连接到机架中的置顶交换机(ToR),然后ToR设备连接到行末端的叶交换机(LEAF)。每台服务器都需要连接到交换网络、存储网络和带外管理网络等网络。
有些数据中心在实施AI时,会将AI集群部署在采用传统架构的服务器集群旁。这时,传统计算有时称为前端网络,AI集群有时称为后端网络。
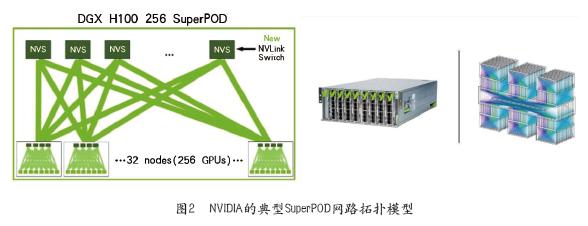
举个例子,可以看看AI领域的领导者NVIDIA提出的架构。NVIDIA的最新GPU服务器是DGXH100,具有4个800G交换机端口(作为8个400GE运行)、4个400GE存储端口以及1GE和10GE管理端口。如图2所示,一个DGXSuper POD可以包含32个这样的GPU服务器,这些GPU服务器可连接到18台交换机。然后,每行将拥有384个400GE光纤链路用于交换机网络和存储网络,还有64个铜缆链路用于管理。因为这种全连接的架构,主机房中光纤链路的数量将大幅增加。
五、布线连接的考虑因素
以NVIDIA为代表的智算设备连接需求已经达到并超越了400G接口速率。智算设备大大推进了400G商业化和800G标准化,并推动产业向1.6T做技术储备。从而为于高性能光纤光缆和高密度连接器提供了巨大舞台。
数据中心建设者需要仔细考虑其AI集群使用哪些光收发器和光缆才能最大限度地降低成本和功耗。光纤连接的总成本中,主要成本集中在收发器上。使用并行光纤的收发器的优势在于,它们不需要使用光复用器和解复用器进行波分复用(WDM),这降低了收发器的成本和功耗。收发器节省下的费用远远抵消了多芯光纤取代双工光缆所略微增加的成本。例如,需要8芯光纤的400G-DR4收发器比采用双工(2芯)光纤的400G-FR4收发器更具成本效益。
高速多模收发器的功耗比单模收发器少一两瓦。举例来说,NVIDIA的典型集群中,单个AI集群具有768个收发器,使用多模光纤的设置将节省高达1.5KW功率。与每个DGXH100消耗的10KW相比,这似乎微不足道,但对于AI集群来说,任何降低功耗的机会都将受到欢迎。任何能够节省功耗的机会都可以大幅降低训练成本和运营支出。
IEEE802.3db将一种新的多模收发器确立为标准,名为VR(超短距离)。该应用针对的是AI集群的列内布线,最大覆盖范围为50米。这些收发器有可能最大程度地降低AI连接的成本和功耗。
另外,许多AI/ML(机器学习)集群使用有源光缆(AOC)来互联GPU和交换机。有源光缆是两端集成了光发射器和接收器的光缆。大多数AOC适用于短距离,通常采用多模光纤。AOC的缺点是它们不具备分离式可插拔收发器所拥有的灵活性。安装AOC是一项耗时的高难度任务,因为布线时必须连带着收发器,需要做好保护;正确安装带有扇出功能(分支功能)的AOC更具有挑战性。据第三方机构的历史统计,AOC的故障率是同等可插拔收发器的两倍;当AOC发生故障时,必须通过机房空间来敷设新的AOC,这会占用数据中心运行时间;当需要升级网络链路时,必须拆除整条旧AOC并更换为新的AOC。随着800G之后,可能CPO技术的商业化,AOC的应用会逐步减少,取而代之的是采用更标准化和结构化的光纤布线系统。
六、结论
AI/ML已经到来,它会成为个人、企业和设备之间交互不可或缺的重要一环。虽然用户可以操作手中的设备来使用AI服务,但这离不开大规模的数据中心基础设施和各方面的支持,企业只有快速高效地训练AI才能在快速变化、高度互联的世界中拥有显著优势。仔细考虑AI集群的布线将有助于节省成本、功耗和安装时间,合理的光纤布线将使企业能够充分受益于人工智能。今天投资部署先进的光纤基础设施来推动AI训练和推理,未来将获得更多令人惊喜的成果。
编辑:Harris

 评论表单加载中...
评论表单加载中...




